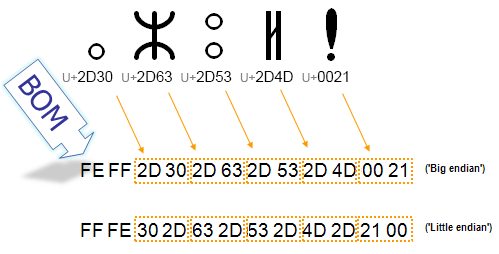
ที่มา : www.dynamicdrive.com/forums
[code lang=”html”]
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Simple JQuery Modal Window from Queness</title>
<script type="text/javascript" src="http://ajax.googleapis.com/ajax/libs/jquery/1.4.2/jquery.js"></script>
<script type="text/javascript">
$(document).ready(function() {
var id = ‘#dialog’;
//Get the screen height and width
var maskHeight = $(document).height();
var maskWidth = $(window).width();
//Set heigth and width to mask to fill up the whole screen
$(‘#mask’).css({‘width’:maskWidth,’height’:maskHeight});
//transition effect
$(‘#mask’).fadeIn(1000);
$(‘#mask’).fadeTo("slow",0.8);
//Get the window height and width
var winH = $(window).height();
var winW = $(window).width();
//Set the popup window to center
$(id).css(‘top’, winH/2-$(id).height()/2);
$(id).css(‘left’, winW/2-$(id).width()/2);
//transition effect
$(id).fadeIn(2000);
//if close button is clicked
$(‘.window .close’).click(function (e) {
//Cancel the link behavior
e.preventDefault();
$(‘#mask’).hide();
$(‘.window’).hide();
});
//if mask is clicked
$(‘#mask’).click(function () {
$(this).hide();
$(‘.window’).hide();
});
});
</script>
<style type="text/css">
body {
font-family:verdana;
font-size:15px;
}
a {
color:#333;
text-decoration:none
}
a:hover {
color:#ccc;
text-decoration:none
}
#mask {
position:absolute;
left:0;
top:0;
z-index:9000;
background-color:#000;
display:none;
}
#boxes .window {
position:absolute;
left:0;
top:0;
width:440px;
height:200px;
display:none;
z-index:9999;
padding:20px;
}
#boxes #dialog {
width:375px;
height:203px;
padding:10px;
background-color:#ffffff;
}
</style>
</head>
<body>
<h2><a href="http://www.queness.com/">Simple jQuery Modal Window Examples from Queness WebBlog</a></h2>
<div style="font-size: 10px; color: rgb(204, 204, 204);">Except where otherwise noted, content on this site is licensed under a Creative Commons Attribution 3.0 License.</div>
<div id="boxes">
<div style="top: 199.5px; left: 551.5px; display: none;" id="dialog" class="window"> Simple Modal Window | <a href="#" class="close">Close it</a> </div>
<!– Mask to cover the whole screen –>
<div style="width: 1478px; height: 602px; display: none; opacity: 0.8;" id="mask"></div>
</div>
</body>
</html>
[/code]