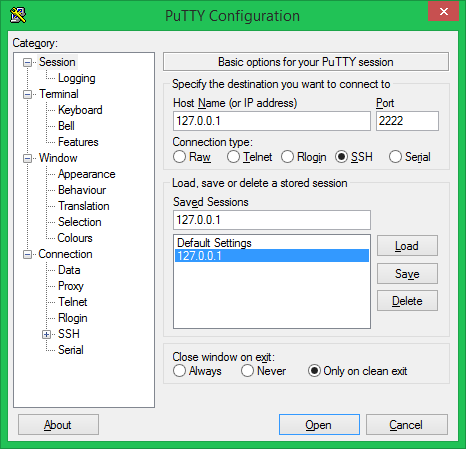
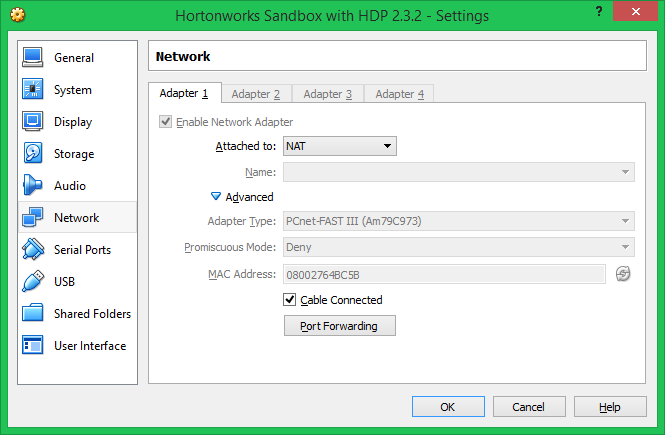
In this section we are going to walk through the process of using Apache Zeppelin and Apache Spark to interactively analyze data on a Apache Hadoop Cluster.
By the end of this tutorial, you will have learned:
- How to interact with Apache Spark from Apache Zeppelin
- How to read a text file from HDFS and create a RDD
- How to interactively analyze a data set through a rich set of Spark API operations